Gemini
1. Google Gemini 3は最新のマルチモーダルAIで、テキスト・画像・音声・動画・コードを統合的に理解・推論できる。
2. 特徴は100万トークンの大規模コンテキストウィンドウ、自律的なエージェント機能、Deep Thinkモード。
3. 学術研究から企業業務の自動化まで幅広く応用され、責任あるAI開発や安全性確保の課題にも取り組んでいる。
本記事は、Googleが開発した最先端のマルチモーダルAI(人工知能)モデルである「Google Gemini(グーグル・ジェミニ)」について、その定義、歴史、最新の技術的特長、そして実践的な応用事例を詳細かつ専門的に解説することを目的としています。特に、2025年11月に発表された最新モデル「Gemini 3」の画期的な性能向上と、それがもたらす産業界および研究分野への影響に焦点を当てます。
Geminiは、単なる大規模言語モデル(LLM)の枠を超え、テキスト、画像、音声、動画、コードなど、異なる種類のデータを統合的に理解し、推論する能力を持っています。この革新的なアプローチは、AI技術のパラダイムシフトを象徴するものであり、今後のデジタル社会の基盤を形成する上で不可欠な知識と言えるでしょう。(出典:Google DeepMind公式情報、2025年)

Image 1: Google Geminiと宇宙のメタファー
1. 用語の定義
Google Geminiは、GoogleのAI開発部門であるGoogle DeepMindによって開発された、マルチモーダル機能を中核とするAIモデル群の総称です。その本質は、従来のAIが別々に処理していた多様なデータ形式(モダリティ)を、単一のニューラルネットワーク構造内で同時に学習し、理解し、関連付け、推論できる点にあります。
1.1. Geminiの基本定義と位置づけ
Geminiは、大規模言語モデル(LLM: Large Language Model)の進化形として位置づけられます。しかし、GPT-4などの初期のLLMが主にテキストデータに基づいて訓練されていたのに対し、Geminiは最初からマルチモーダル(多感覚統合型)として設計されました。これは、人間が視覚、聴覚、言語などを統合して世界を理解するのと同様に、AIも多様な情報を同時に処理することで、より高度で複雑な推論能力を獲得するという思想に基づいています。
初期リリースは2023年12月6日(Gemini 1.0)であり、現行の最新世代は2025年11月18日に発表された「Gemini 3」シリーズです。モデルラインナップは、性能とサイズの異なるUltra、Pro、Flash、そして組み込み用途向けのNanoなど多岐にわたります。(出典:Google公式ブログ「Introducing Gemini: Google’s most capable AI model yet」、2023年)
1.1.1. マルチモーダル性とは
Geminiにおけるマルチモーダル性とは、単に複数のデータ形式を個別に受け付けて処理する能力を指すのではありません。真のマルチモーダルAIは、以下のような統合的な処理が可能です。
- テキストと画像の統合: 画像の内容をテキストで説明し、その説明に基づいて画像を編集、または関連するコードを生成する。
- 動画と音声の統合: 動画コンテンツを視聴し、そこで話されている内容(音声)と映っているシーン(視覚情報)を同時に分析し、動画全体の要約や、特定の事象が発生した時刻を特定する。
- コードとテキストの統合: 自然言語によるプロンプト(指示)から、特定のプログラミング言語のコードを生成し、さらにそのコードの挙動をシミュレーションして説明する。
この統合的な理解こそが、Geminiが従来のLLMと一線を画す最大の特長です。
1.2. 主要な技術的構成要素
Geminiの高度な知性を支えるのは、以下の革新的な技術的要素です。
1.2.1. ネイティブなマルチモーダルアーキテクチャ
Geminiのモデルは、異なるデータ形式を扱うために、個別のエンコーダーやモジュールを組み合わせる「モジュール型アプローチ」ではなく、最初から単一の効率的なアーキテクチャ内で、すべてのモダリティを処理するように設計されています。この「ネイティブ・マルチモーダル」アプローチにより、データ間の関係性をより深く理解し、推論の際の遅延(レイテンシ)を最小限に抑えることが可能になりました。(出典:Google DeepMind技術レポート、2023年)
1.2.2. 大規模なコンテキストウィンドウ
Gemini 3 Proでは、最大100万トークン(約70万語に相当)という、驚異的なコンテキストウィンドウをサポートしています。これは、AIが一度に記憶し、参照できる情報の量を意味します。この容量により、約1時間分の無音動画、約11時間分の音声、または約30,000行のコードを一気に読み込み、その全体的な文脈を把握した上での正確な回答生成が可能になります。従来のAIモデルでは、長大な文書や動画の全体像を捉えることが難しく、文脈の逸脱(コンテキストロスト)が問題となっていましたが、Geminiはこの課題を克服しています。
| モダリティ | 容量 | 備考 |
|---|---|---|
| テキスト | 約70万語 | 専門書数冊分に相当 |
| コード | 約30,000行 | 大規模なソフトウェアプロジェクトの一部をカバー |
| 音声 | 約11時間 | 長時間の会議や講義録の要約が可能 |
| 動画 | 約1時間(無音) | 視覚的な変化と時間軸の推論をサポート |
1.2.3. エージェント機能と長期計画立案能力
Gemini 3は、単に質問に答えるだけでなく、一連のタスクを自律的に実行するAIエージェントとしての機能が強化されています。具体的には、長期計画立案能力(Long-Term Planning)が大幅に向上しており、複雑な多段階のタスクを分解し、ツールの使用、意思決定、そして途中のフィードバックを取り入れながら、一貫した目的を維持して実行に移すことができます。
ベンチマークVending-Bench 2において、Gemini 3は最高評価を獲得し、1年間のシミュレーション期間にわたる持続的なツール使用と意思決定の一貫性が実証されました。これは、実世界のビジネスプロセス自動化や、自律的なソフトウェア開発アシスタントとしての将来的な応用を強く示唆しています。(出典:Google DeepMind、2025年11月)
1.2.4. Deep Thinkモード
Gemini 3シリーズには、高度な問題解決のための特別なモード「Deep Thinkモード」が搭載されています。このモードは、モデルに問題をより深く、より長い時間をかけて熟考させ、複数の推論経路を探索させることで、標準モードでは到達できないレベルの精度を実現します。Humanity’s Last Exam(HLE)で41.0%、GPQA Diamondで93.8%という驚異的なスコアを記録しており、特に博士レベルの複雑な推論タスクにおいて、その真価を発揮することが期待されています。(出典:Google公式ブログ、2025年11月)
2. 用語の背景と歴史
Google Geminiの開発史は、AI技術の競争激化と、GoogleのAI戦略の転換を反映しています。その起源は、OpenAIのChatGPTが巻き起こした生成AIブームへの、Googleによる戦略的な対応として捉えることができます。
2.1. 誕生の契機と初期の取り組み
2022年11月、OpenAIがChatGPTを公開し、世界中で瞬く間に利用者を増やしたことは、検索ビジネスを主要な収益源とするGoogleにとって、看過できない脅威となりました。これに対抗するため、Googleは長年培ってきたAI研究の成果を集結させ、プロジェクトを加速させました。
- 2023年2月: Geminiの前身となるチャットボット「Bard(バード)」を発表。当初はGoogle独自の対話型LLMであるLaMDA(Language Model for Dialogue Applications)を基盤としていました。
- 2023年4月: Googleの主要AI研究部門である「Google Brain」と「DeepMind」が統合され、Google DeepMindが設立されました。これは、GoogleのAI研究資源を集中させ、Geminiのような最先端モデルの開発を加速させるための組織再編でした。(出典:Google公式プレスリリース、2023年4月)
- 2023年5月: Google I/Oにて、Bardの基盤モデルをPaLM 2へと移行することを発表。これは、マルチリンガル性能と推論能力の向上をもたらしました。
2.2. Gemini 1.0の発表とマルチモーダルの確立
Geminiプロジェクトの成果として、2023年12月6日、最初のメジャーバージョンとなる「Gemini 1.0」が正式に発表されました。この発表は、GoogleがAIの主導権を奪還するための決定的な一歩と位置づけられました。
- Gemini 1.0の特徴:
- Ultra(最大性能モデル)、Pro(幅広いタスク向け)、Nano(デバイス上実行モデル)の3つのサイズで提供開始。
- 主要なベンチマークにおいて、当時の最先端モデルであるGPT-4を一部上回る性能を示しました。
- 特に、画像、音声、テキストを統合的に処理するネイティブ・マルチモーダル機能が、他の競合モデルとの差別化要因となりました。(出典:Google公式ブログ「Introducing Gemini」、2023年12月)
- 2024年2月8日: チャットサービス「Bard」が正式に「Gemini」へと名称を変更し、ブランドの統一が行われました。これにより、GoogleのAIサービスはGeminiを中心に展開されることになりました。同時に、より高度な機能を提供する有料プラン「Gemini Advanced with Ultra 1.0」が発表されました。
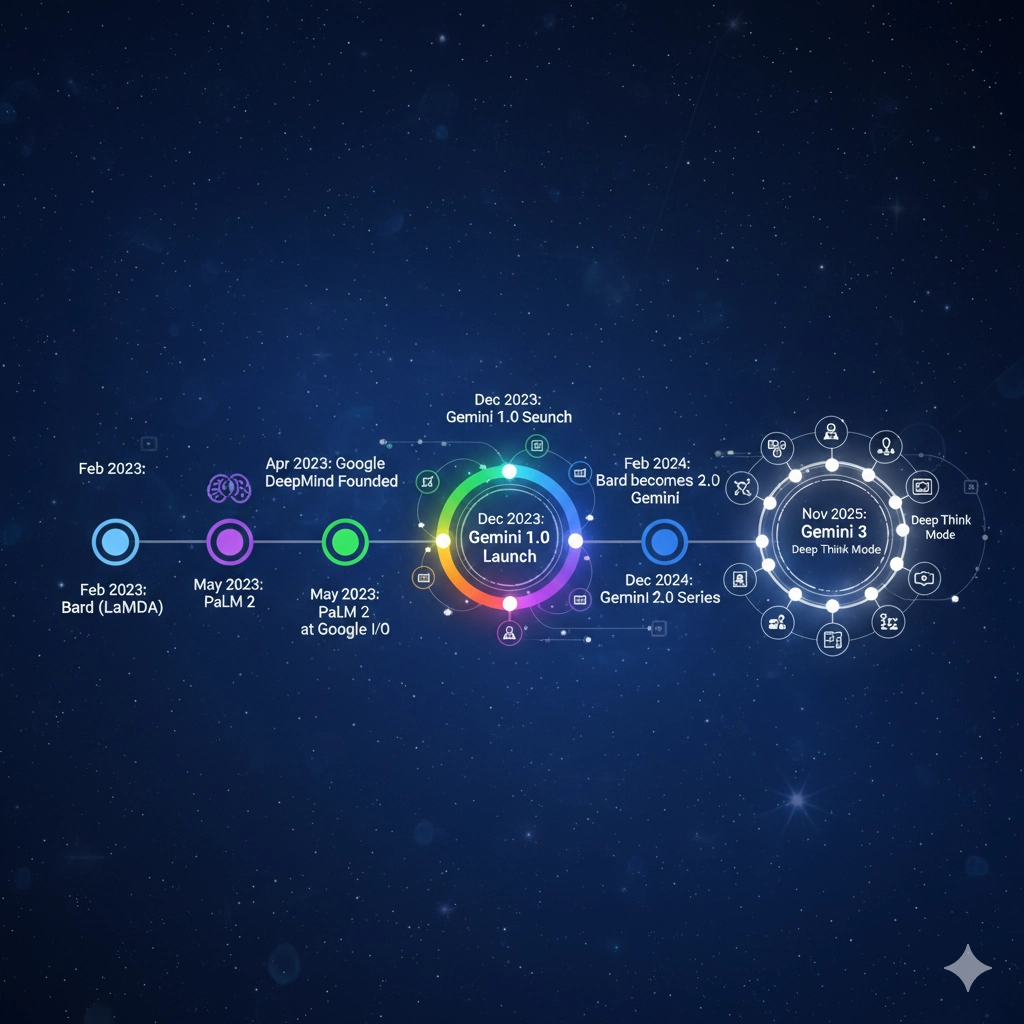
Image 2: Google Gemini開発史の主要マイルストーン
2.3. Gemini 2.0と2.5の進化
2024年を通じて、Geminiは継続的なアップデートを重ねました。特に2024年後半にリリースされたGemini 2.5シリーズは、実用性と効率性を大幅に向上させました。
- コンテキストウィンドウの拡大: Gemini 2.5 Pro/Flashは、標準で100万トークンという超大規模なコンテキストウィンドウをサポート。これにより、長文の文書や大規模なデータセットを一挙に分析する能力が実用レベルに達しました。
- Flashモデルの導入: Gemini 2.5 Flashは、高速でコスト効率が高い汎用モデルとして導入されました。これは、遅延が重視されるWebアプリケーションやリアルタイムの対話処理において、高性能と低コストを両立させることを可能にしました。
- 思考機能の搭載: Flashモデルを含むすべてのGemini 2.5シリーズに、モデルが推論ステップを内部的に実行する「思考機能(Thinking)」が搭載されました。これにより、モデルはより複雑な指示や論理的タスクを、より少ないトークン数で正確に処理できるようになりました。(出典:Google Developers Blog、2024年)
2.4. Gemini 3の登場と「Deep Think」の革新
そして2025年11月18日、Googleは最新かつ「これまでで最も知的なモデル」と位置づける「Gemini 3」を発表しました。Gemini 3は、推論能力、マルチモーダル理解、そしてエージェント機能のすべてにおいて、従来のAIの限界を大きく押し広げました。(出典:CNBC「Google announces Gemini 3 as battle with OpenAI intensifies」、2025年11月18日)
特に注目すべきは、以下の画期的な成果です。
- LMArenaリーダーボードでの首位獲得: 複雑な質問応答タスクにおいて、1501 Eloという記録的なスコアを達成し、他のすべての競合モデルを凌駕しました。
- 博士レベルの推論能力: Humanity’s Last Exam(HLE)で37.5%(Deep Thinkモードで41.0%)という高得点を記録。これは、高度な学術知識を要する試験で、人間と同等、あるいはそれを超えるレベルの専門的な推論が可能であることを示しています。
- エージェント機能の深化: WebDev ArenaやSWE-benchといったコーディング関連のベンチマークで高い評価を受け、自律的なソフトウェア開発エージェントとしての実用性が証明されました。
Geminiの歴史は、テキスト中心のLLMから、知覚・推論・行動を統合する真のマルチモーダルAIエージェントへの移行という、現代AIの方向性を体現していると言えるでしょう。
3. 用法と具体例
Google Geminiは、そのマルチモーダル機能と高度な推論能力により、一般ユーザー向けチャットボットから企業向けソリューション、そして開発者向けツールに至るまで、極めて広範な領域で活用されています。ここでは、最新モデルであるGemini 3の具体的な用法と、それがもたらす革新的な具体例を紹介します。
3.1. 一般ユーザー向けの利用法(Geminiアプリ)
一般ユーザーは、ウェブ版(gemini.google.com)やモバイルアプリ(Android/iOS)を通じてGeminiにアクセスできます。有料プラン「Google One AI Premium」に登録することで、最新のGemini 3 ProやDeep Thinkモードへの優先アクセス権が得られます。
- マルチモーダル検索と学習:
- 例1: 画像分析と説明: ユーザーが珍しい植物の写真をアップロードし、「この植物の名前、原産地、そして育て方を教えてください」と指示すると、Geminiは画像から種を特定し、関連するテキスト情報、動画、そして地理情報を統合して詳細な回答を生成します。
- 例2: 動画の要約と特定シーンの抽出: ユーザーが長時間の講義動画のURLを入力し、「この動画の冒頭10分間を要約し、さらに『量子コンピューティング』という単語が初めて使われたタイミングとその文脈を教えてください」と指示すると、Geminiは動画と音声を同時に分析し、ピンポイントで情報を抽出します。
- パーソナライズされたAIエージェント:
- Google Workspaceとの連携: Gmailの受信トレイを分析し、「今週の会議の決定事項を抽出し、それに基づいて来週のタスクリストをGoogle Docsに作成してください」といった複雑な指示を、Geminiエージェントが自動で実行します。(出典:Google Cloud「Gemini Enterprise」、2025年)
- 旅行計画の自動化: ユーザーが「来月の大阪旅行の計画を立てたい。予算は10万円で、文化的な観光地とグルメを優先して」と入力すると、Google マップやフライト情報、YouTubeの観光動画などを統合的に参照し、詳細な日程表をGoogle Sheetsに自動で作成します。

Image 3: Gemini 3 Proのマルチモーダル応用例
3.2. 開発者向けの利用法(Gemini API / Google AI Studio)
開発者は、Gemini APIやGoogle AI Studioを通じて、Geminiの能力を独自のアプリケーションに組み込むことができます。Gemini 3は、特にコーディング能力とエージェント機能が強化されており、以下の分野で利用されています。
- 自律的なソフトウェア開発エージェント:
- バグ修正とコード生成: 開発者がGitHubのリポジトリのURLと「このバグを修正するためのコードを、Pythonで書いてください。テストコードも追加してください」という指示を入力すると、Gemini 3はリポジトリのコードベース全体を読み込み、変更箇所とテストを自動で提案、実行します。(SWE-bench Verifiedで76.2%のスコアを記録)
- Webサイトのプロトタイプ生成: デザインツール(例:Figma)のスクリーンショットをGeminiに渡し、「このレイアウトをReactコンポーネントとして実装し、レスポンシブデザインに対応させてください」と指示すると、Geminiは即座にコードを生成します。
- 高度なデータ分析と推論:
- 研究論文の解析: 開発者が複雑な物理学の論文(PDF形式)と関連する実験データ(CSV形式)をアップロードし、「この実験結果から、提示された理論の妥当性を評価し、矛盾点を指摘してください」と指示すると、Geminiは両方のデータを照合し、学術的な推論を行います。(GPQA Diamondで91.9%のスコアを記録)
- 構造化出力: Gemini 3 Proは、JSONやXMLといった特定のデータ構造(スキーマ)に従った正確な出力生成をサポートしています。これにより、AIの出力を直接データベースや他のシステムに組み込むことが容易になります。
3.3. 企業向けの利用法(Google Cloud Vertex AI / Gemini Enterprise)
大企業は、Google Cloud Vertex AIを介してGeminiをセキュアな環境で利用できます。特に、データプライバシーとコンプライアンスが重視される金融、医療、製造業での活用が進んでいます。
- Gemini Enterprise: 企業内の独自のデータとGeminiを接続し、従業員の生産性を向上させるためのソリューションです。
- 社内知識検索: 企業が持つ数百万件の内部文書(設計図、契約書、メール履歴など)をVertex AIにアップロードすることで、Geminiがそれを学習し、「特定のプロジェクトにおける過去の顧客との交渉経緯」といった複雑な質問に対し、正確な一次情報(グラウンディング)に基づいた回答を生成します。
- 製造業の品質管理: 製造ラインで撮影された大量の動画やセンサーデータをGeminiがリアルタイムで分析し、人間の目では見逃しがちな微細な欠陥や異常を早期に検知します。(出典:Google Cloud Next ’25 カンファレンス情報)
- カスタマイズとファインチューニング: 企業は、Geminiモデルを自社の特定の業務や専門用語に合わせてファインチューニング(微調整)することが可能です。これにより、業界固有のタスクに対するAIの精度を極限まで高めることができます。
Geminiの応用は、単なる文章生成や情報検索に留まらず、企業の意思決定支援、ソフトウェアの自動開発、そして複雑な物理世界の分析と推論といった、AIエージェントによる業務自動化の領域へと本格的に移行していると言えるでしょう。
4. 関連語句と概念
Google Geminiを深く理解するためには、それが関連する広範なAI分野の専門用語と概念を整理しておく必要があります。特に、AIの進化の方向性を示す重要な概念と、競合する技術について解説します。
4.1. 中核となる概念
4.1.1. マルチモーダルAI(Multimodal AI)
Geminiの最も重要な特長であり、テキスト、画像、音声、動画、コードなど複数のデータ形式を、単一のモデル内で統合的に学習・理解・処理するAIを指します。従来のAIが単一のモダリティ(例:LLMはテキストのみ)に特化していたのに対し、マルチモーダルAIは人間のように複合的な感覚情報から推論を行うため、より複雑なタスクや実世界のシナリオへの対応力が高まります。
- 対義語: ユニモーダルAI(Unimodal AI)
- 補足: 複数のモダリティに対応しているだけでも、それぞれを別々のモデルで処理し、その結果を統合するアプローチ(モジュール型)もあります。Geminiは、学習段階からすべてを統合する「ネイティブ・マルチモーダル」である点が革新的です。
4.1.2. 大規模言語モデル(LLM: Large Language Model)
大量のテキストデータで学習された、人間の言語を理解し、生成する能力を持つニューラルネットワークです。Geminiもその基盤としてLLM技術(トランスフォーマー・アーキテクチャ)を採用していますが、前述の通りマルチモーダル機能へと拡張されています。LLMは、自然言語処理(NLP)分野のブレークスルーであり、AIチャットボットやコンテンツ生成の基盤となっています。(出典:Google AI Glossary)
4.1.3. コンテキストウィンドウ(Context Window)
AIモデルが一度に処理・記憶し、推論の材料とすることができる入力データの最大量を指します。トークン(単語や文字の単位)数で表され、Gemini 3 Proの100万トークンは、その情報処理能力の高さを示す主要な指標です。コンテキストウィンドウが広いほど、モデルは長文の文脈や、会話の履歴全体を正確に把握し続けることができます。長距離依存性(Long-range dependency)の問題解決に不可欠な要素です。
4.2. 関連する技術用語
4.2.1. 推論(Inference)と推論能力(Reasoning Capability)
AIにおける推論とは、入力データ(プロンプト)に基づき、論理的な思考ステップを経て結論や答えを導き出すプロセスです。推論能力は、AIの知性の核心であり、単なるパターンマッチングではなく、複雑な問題解決や未知の状況への対応力を意味します。Gemini 3の「博士レベルの推論能力」は、学術的な知識と論理構造を深く理解し、それらを応用する高度な能力を指します。
4.2.2. エージェントAI(Agent AI)
特定の目標を達成するために、環境を認識し、計画を立て、自律的に行動を実行できるAIシステムです。従来のLLMが「思考」するのみであったのに対し、エージェントAIは「行動」します。Gemini 3の長期計画立案能力やツール使用機能(Function Callingなど)の強化は、このエージェントAIとしての進化を強く示しており、将来的にユーザーの業務を完全に自動化することが期待されています。
4.2.3. グラウンディング(Grounding)
AIの回答を、具体的な情報源や現実世界の事実に基づかせるプロセスです。Geminiでは、Google検索や企業内の独自データ(Vertex AI利用時)をリアルタイムで参照し、その情報に基づいて回答を生成することで、AIが作り話をする現象(ハルシネーション)を抑制します。回答に参照元を明記する機能も、グラウンディングの一環です。
4.3. 競合モデルとの関係
Google Geminiは、以下の主要なAIモデルと激しい競争を繰り広げています。
| モデル名 | 開発元 | 主な特長 |
|---|---|---|
| GPT-5(予想) | OpenAI | 市場シェアを誇るLLMの王者。強力なテキスト生成能力と推論能力。Gemini 3の最大の直接競合。 |
| Claude 3.5 / 4(予想) | Anthropic | 安全性(Constitutional AI)と長文理解に強み。人間的で自然な対話能力が高い。 |
| Llama 3 / 4(予想) | Meta | オープンソース戦略の中核モデル。コミュニティによる開発・改良が活発。 |
Geminiの競争優位性は、Googleの広大なエコシステム(検索、Gmail、YouTubeなど)への統合と、ネイティブなマルチモーダル機能への早期からの注力にあります。特にGemini 3の登場により、AIの性能競争は「単なるテキスト生成」から「複雑な推論と自律的な行動」の領域へと完全にシフトしたと言えるでしょう。
5. 応用と実践的知識
Google Geminiは、その高度な機能から、学術研究、産業応用、そして日常生活の効率化に至るまで、幅広い分野で革新的な実践的知識とソリューションを提供しています。特にGemini 3の登場により、これまでのAIでは困難だった、批判的で発展的な応用が可能となっています。
5.1. 学術研究と批判的分析への応用
Gemini 3の博士レベルの推論能力は、特に科学技術(STEM)分野における研究効率を劇的に向上させることが期待されています。
- 複雑な学術論文のレビューと検証:
- 実践例: 研究者が、自身の専門分野とは異なるが関連性の高い、数百ページに及ぶ学術論文のPDFファイルと、その理論的根拠を示す数十枚のグラフ画像をGeminiに提供します。Geminiは、Deep Thinkモードを活用し、論文の主張の論理的整合性、提示されたデータの統計的妥当性、そして既存の専門家コンセンサスとの矛盾点を、数時間かけて詳細に分析し、批判的なレビューレポートを生成します。
- 意義: これは、単なる要約ではなく、人間が行う学術的レビューに匹敵する、知識の応用と構造的な推論を伴う作業であり、研究のボトルネック解消に貢献します。
- 科学的仮説の自動生成と評価:
- 実践例: バイオインフォマティクスの研究において、特定の遺伝子配列データと、そのタンパク質の3D構造モデル(画像/ファイル)をGeminiに与え、「このタンパク質の特定の変異が、どのような生理学的機能変化をもたらすか」について、既知の文献情報と構造から予測し、複数の新たな仮説を立案させます。
5.2. 産業界における課題解決と将来展望
Geminiのエージェント機能は、企業の業務プロセス全体の自動化を可能にする「企業AIエージェント」の実現に向けたロードマップの中核を担っています。(出典:Google Cloud「Gemini Enterprise」、2025年10月)
5.2.1. 自律的なエージェント機能の活用
Gemini 3が持つ長期計画立案能力は、複雑なビジネスプロセス自動化の課題を解決します。例えば、新しいマーケティングキャンペーンの実行指示を受けたAIエージェントは、以下の多段階タスクを自律的に実行できます。
- 過去のキャンペーンデータ(Google Sheets/Drive)を分析し、最適なターゲット層を特定する。
- ターゲット層に響くキャッチコピーとビジュアルをGemini 3 Pro Imageで生成する。
- 生成された素材を基に、Google広告プラットフォームでキャンペーンを設定する。
- 設定後もリアルタイムのパフォーマンスを監視し、予算やクリエイティブの自動調整を行う。
この一連のプロセスを、人間が細かい指示を出すことなく、AIが自律的に、かつ一貫した目的(ROIの最大化など)をもって実行する点が、従来の自動化ツールとの決定的な違いです。
5.2.2. セキュリティとインシデント対応
Geminiの強力なコード理解能力と推論能力は、サイバーセキュリティ分野にも応用されています。Terminal-Bench 2.0で54.2%のスコアを記録するなど、セキュリティ分野での高い実用性が示されています。
- 実践例: 大量のネットワークログファイルと、特定のマルウェアのバイナリファイルがGeminiに提供されます。「このログの異常は何を意味するか?そして、このマルウェアのソースコード(逆アセンブル結果)に基づいて、最も脆弱なシステム構成を特定せよ」という指示に対し、Geminiは膨大なデータの中から脆弱性を特定し、具体的な対策コードを提案します。
5.3. 倫理的な課題と責任あるAI開発
Geminiのような高性能AIの普及は、その倫理的な運用に関する課題も同時に提起しています。Googleは、Frontier Safety Frameworkに基づき、責任あるAI開発を推進しています。
- 透明性の確保: Geminiの性能と限界に関する情報を「モデルカード」として公開し、ユーザーと開発者に対し、AIの能力について過度な期待を持たせないよう努めています。
- バイアスの低減と公平性: 大規模な訓練データに含まれる歴史的なバイアスが、AIの出力に影響を与える可能性があるため、データセットの精査やRLHF(Human Feedbackによる強化学習)を通じて、公平で差別的でない回答を生成するための継続的な取り組みが行われています。
- 誤用(プロンプトインジェクション)対策: Gemini 3は、悪意のあるプロンプト(指示)によってAIが意図しない行動を取らされるリスク(プロンプトインジェクション)に対する耐性が大幅に向上しています。これは、AIシステムの信頼性を確保する上で極めて重要な技術的課題です。(出典:Google DeepMind安全性評価レポート、2025年)
Geminiの進化は、AIが人類の知識と生産性を飛躍的に高める一方で、その能力に見合った社会的責任と安全性の確保が最優先されるべきであることを示しています。将来的にAIがさらに自律化するにつれて、これらの倫理的・安全性の課題への取り組みが、AI技術の持続的な発展を左右することになるでしょう。
6. Q&Aセクション

Q1: GeminiとChatGPT(GPT-4/GPT-5)の最も大きな違いは何ですか?
A: 最大の違いは、ネイティブなマルチモーダル性です。Geminiは、テキストだけでなく、画像、音声、動画、コードといった複数のデータ形式を、単一のモデルで同時に学習・理解・推論するように最初から設計されています。これにより、特に複数の情報源を統合して理解するタスクや、動画・音声の分析において、Geminiは強力な性能を発揮します。ChatGPTもマルチモーダル機能を追加していますが、Geminiは設計思想の根幹からマルチモーダルである点が異なります。また、最新のGemini 3は、長期計画立案能力と博士レベルの推論能力において、ベンチマークで高いスコアを記録しています。
Q2: Gemini 3の「Deep Thinkモード」とは具体的にどのような機能ですか?
A: Deep Thinkモードは、Gemini 3 Proに搭載された特別な推論モードです。このモードを有効にすると、AIは回答を生成する前に、問題をより深く、より長い時間をかけて熟考し、複数の複雑な推論ステップを内部的に実行します。これにより、標準モードでは難しかった極めて高度な論理的・学術的な問題(例:Humanity’s Last Exam)の解決精度が向上します。これは、より多くの計算資源と時間を費やすことで、モデルの持つ潜在的な知性を最大限に引き出すための機能と言えます。
Q3: 開発者がGeminiを始めるのに最適なモデルは何ですか?
A: 開発者がまず始めるには、Gemini 2.5 Flashが最適です。このモデルは、高速性(低遅延)とコスト効率に優れながら、100万トークンのコンテキストウィンドウや思考機能といったGeminiの主要な特長を保持しています。ほとんどの汎用的なタスク(チャットボット、要約、翻訳、簡単なコード生成)において十分な性能を発揮します。より複雑な推論タスクや、高度なマルチモーダル分析が必要な場合は、Gemini 3 Proへの移行を検討するのが良いでしょう。
Q4: Geminiは日本語の処理能力についても優れていますか?
A: はい。Geminiは、マルチリンガル機能についても強力な性能を有しています。特にGemini 2.5シリーズ以降、日本語を含むアジア言語への対応が強化されており、長文の日本語文書の理解、複雑な文脈の把握、そして自然な日本語の生成において、高い評価を受けています。Googleは、日本語を含む多様な言語のデータでモデルを訓練しており、日本の企業や開発者にとっても非常に実用性の高いモデルです。(出典:Google AI for Developers、言語対応情報)
Q5: 企業がGeminiを安全に利用するにはどうすればよいですか?
A: 企業がセキュリティとプライバシーを確保してGeminiを利用するには、Google Cloud Vertex AIを経由することが強く推奨されます。Vertex AIを利用することで、企業のデータはGoogle Cloudのセキュアな環境内に留まり、AIモデルのカスタマイズ(ファインチューニング)や、アクセス制御、コンプライアンス要件への対応が容易になります。また、Gemini Enterpriseソリューションを利用することで、企業独自のデータに基づいたグラウンディングが可能となり、より安全で正確な社内AIシステムの構築が可能です。
関連情報
関連記事


