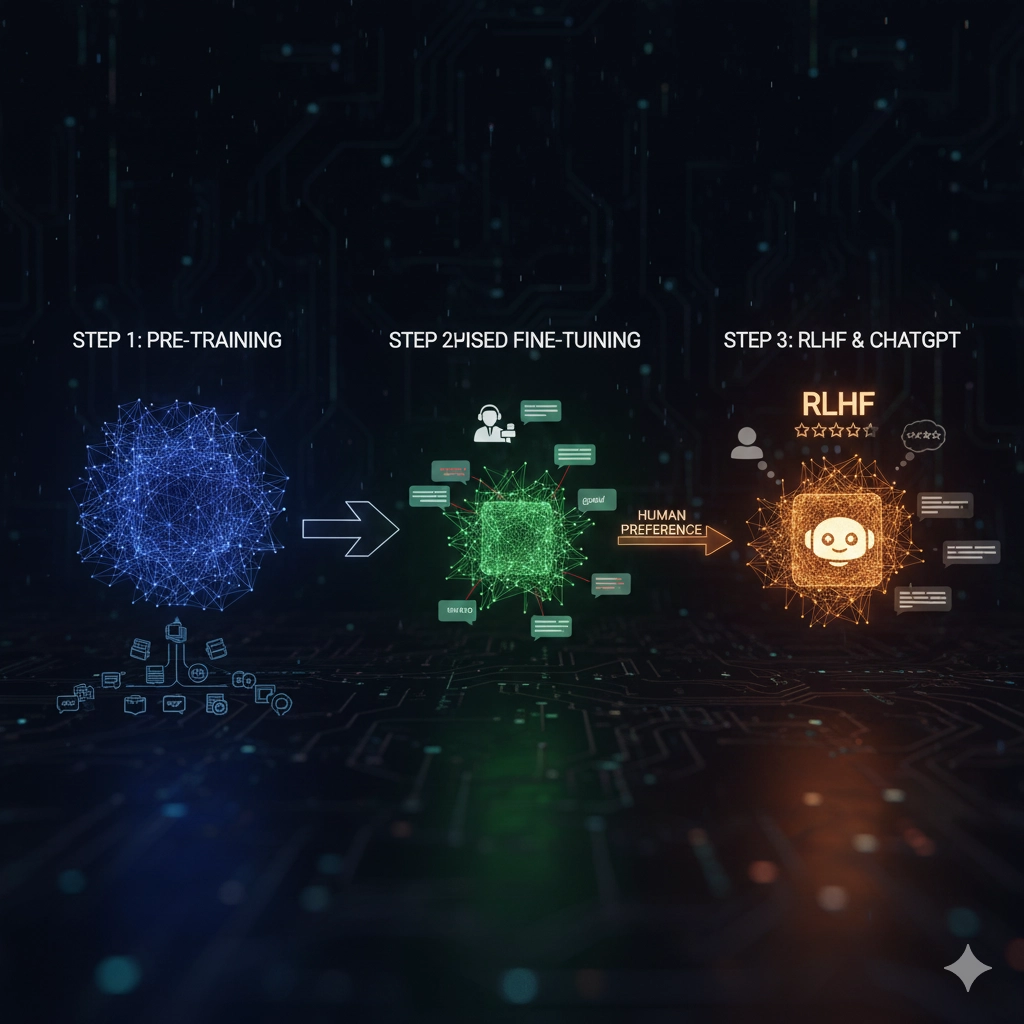
1. ChatGPTとは
GPTアーキテクチャの特徴は、非常に多くのパラメータを持つトランスフォーマーモデルを利用していることです。具体的には、GPT-3では約1750億ものパラメータを駆使し、膨大なインターネットデータを事前に学習することで、文法・文脈理解の能力を高めています。これにより、ユーザーからの多様な質問に対し、自然で人間的な応答が可能となっています。
また、この技術を支えているのが、RLHF(人間のフィードバックからの強化学習)という手法です。この手法では、モデルが生成するテキストを人間の評価者が評価し、そのフィードバックを基に強化学習を行うことで、より高品質な応答が生成できるようにモデルが調整されます。
強化学習のプロセスでは、探索と利用の両立が重要です。モデルは、様々な応答パターンを試行して(探索)、効果的なパターンを選び出し(利用)、その結果を応答に反映させます。これを繰り返すことで、より自然で高品質な対話が可能となります。
RLHFにより、ユーザーエクスペリエンスが大きく向上します。ユーザーからのフィードバックを活かし、AIが個々のユーザーに適した応答を生み出すことで、対話のリアリティが増し、AIとの交流が滑らかになります。
結果として、ChatGPTは、強力なトランスフォーマーモデルと高度なRLHF技術によって支えられており、さらなるAI対話システムの進化が期待されています。
2. GPTアーキテクチャの概要
GPT-3は約1750億のパラメータを備えています。この膨大な数のパラメータが、テキストの生成と理解において非常に高い精度をもたらし、人間に近い自然な対話を実現するための基盤を形成しています。そして、GPT-4はさらに多くのパラメータを導入し、その能力を一層拡大しています。
このような大規模なモデルを動かすためには、インフラとリソースが非常に重要です。運用にあたっては、計算リソースの最適化と効率的な処理が求められています。こうした技術的要件を満たすことで、ますます複雑で高度なAIモデルが進化を遂げていくのです。
また、GPTアーキテクチャは自己教師あり学習の技術を活用しています。これは大量のテキストデータを通じてモデルが自ら学習を行い、文法や文脈、語彙の使い方を効果的に習得する方法です。この学習によって、単なるキーワードの羅列ではなく、文法的に正確で文脈に応じた受け答えが可能となります。
総じて、GPTは自然言語処理のフィールドにおいて画期的な進化を示しています。これらのモデルが示す高精度な生成能力は、AIの応用範囲を著しく拡大し、今後の技術革新の基礎となるでしょう。
3. 自己教師あり学習とその効果
自己教師あり学習の主な利点は、一からデータをラベル付けする必要がないことです。この手法では、既存の大量のデータを用いて言語モデルをトレーニングするため、時間とコストの大幅な削減に繋がります。また、この方法によりモデルが自分自身でエラーを修正しつつ学び続けることが可能になり、長期的に見て非常に効率的です。
具体的な効果として、ChatGPTは高度な文法理解と文章生成能力を持つようになります。これにより、複雑な指示や質問にも柔軟に対応でき、ユーザーに対して満足のいく対話体験を提供することが可能です。例えば、異なるトピックに直面しても、以前の対話の内容を踏まえつつ新たな情報を加えて一貫した応答を作成することができます。
このモデルの特徴的な機能として、人間らしい文脈の把握が挙げられます。それにより、単なる情報の提供にとどまらない、対話の流れを意識した回答を行うことができるのです。さらに、インターネットデータをベースにした文脈理解は、モデルが常に最新のトピックやトレンドを把握していることを意味します。
その結果、自己教師あり学習によってChatGPTは日々成長し続け、ユーザーにとってより効果的なコミュニケーションの手段となるのです。これにより、学習の過程を継続することで、さらに高度な対話システムの実現が期待されます。
4. RLHF(人間のフィードバックからの強化学習)の役割
この技術は、モデルが生成するテキストの質を向上させるための肝心なプロセスとして注目されています。
まず、AIが生成する複数の回答を人間が評価し、どれが最も優れているかを判断します。
この評価を基に、AIは自身を改善し、より良質な回答を提供できるようになります。
RLHFのプロセスの中で特に重要なのが、「探索と利用のバランス」です。
ここでは、AIは多様な応答パターンを試み(これが探索の部分)、その中から最も有用なパターンを学び取ります(これが利用)。
このサイクルが繰り返されることで、AIの応答の自然さと品質が向上します。
ユーザーとの対話がより現実的で滑らかになるのは、この強化学習の賜物と言えるでしょう。
また、RLHFは単にテキストの品質向上だけでなく、ユーザーの体験を大幅に改善する点でも優れています。
ユーザーからの直接的なフィードバックを基に、AIは個々のユーザーにより適した、現実感あふれる応答を生成できるよう調整されます。
このため、AIと人間との対話は、単なる情報交換にとどまらず、より人間味のあるコミュニケーションへと発展しています。
このようにしてChatGPTは、トランスフォーマーモデルとRLHFを組み合わせた技術を背景に、現在も進化を続けています。
将来的にも両技術の更なる進化が期待されており、それによってより高性能で有用なAI対話システムが誕生することでしょう。
5. ChatGPTのユーザーエクスペリエンスへの影響
具体的なプロセスとしては、ユーザーから提供された様々なフィードバックを基に、システムが生成する回答の質を向上させます。これには、ユーザーがどのような応答を期待しているかという感覚をシステムが学習することが含まれます。これにより、ユーザーは自分により適した、パーソナライズされた体験を得ることができます。
さらに、AIと人間との対話を効果的にするための仕組みとしてもフィードバックは重要です。応答の内容を修正し、より人間らしいコンテキストを持たせるための調整が継続的に行われています。これにより、ユーザーはまるで人間と対話しているかのように感じることができ、AIとのコミュニケーションの質が格段に向上します。
最終的に、こうした進化によって、ChatGPTはユーザーにとってますます有益で親しみやすいツールとなり得ます。フィードバックに基づいた応答の向上こそが、AIと人間の対話をより円滑に、そして効果的にするための鍵となるのです。
6. 最後に
まず、トランスフォーマーモデルとRLHF(Reinforcement Learning from Human Feedback)という2つの重要な技術的要素が挙げられます。トランスフォーマーモデルは、多数のパラメータを活用し、テキストの生成と理解を支える中核として機能しています。一方で、RLHFは、そのパラメータの調整をサポートし、より自然で適切な応答を可能にしています。
これらの技術がまさに進化し続けることで、精度の高いAIの対話能力がさらに向上すると予想されます。具体的には、AIが学習する際、人間からのフィードバックを取り入れるRLHFの進化により、ユーザーに対してますますパーソナライズされたコミュニケーションが可能になるでしょう。AIは、ただ単に情報を提供するだけでなく、ユーザーの意図を察知したり、感情や文脈を理解したりする能力が大幅に向上することが期待されています。
また、トランスフォーマーモデル自体も、さらなる研究と開発を通じて、より高性能で効率的なアルゴリズムに進化するでしょう。一つの可能性は、エネルギー効率の改善や、学習速度の向上です。これにより、AIはより大規模なデータセットを短時間で処理し、さまざまなシナリオにおいて迅速に適応する能力を持つことが期待されます。
将来のAI対話システムには、今以上に柔軟で人間らしい応答が求められるようになるでしょう。これに伴い、ユーザー体験が大きく変わる可能性があります。AI技術の進化は、社会的にも大きなインパクトを与え、さまざまな分野での活用が一層進むことでしょう。
総じて、トランスフォーマーモデルとRLHFが組み合わされたAIが、今後どのように進化するかに注目が集まっています。未来のAI対話システムは、更なる技術革新により、現状を超える能力と有用性を持つことが期待されています。


コメント